Performance Evals
Performance evals measure the latency and memory footprint of an Agent or Team.
Basic Example
1"""Run `uv pip install openai kern-ai memory_profiler` to install dependencies."""23from kern.agent import Agent4from kern.eval.performance import PerformanceEval5from kern.models.openai import OpenAIResponses678def run_agent():9 agent = Agent(10 model=OpenAIResponses(id="gpt-5.2"),11 system_message="Be concise, reply with one sentence.",12 )1314 response = agent.run("What is the capital of France?")15 print(f"Agent response: {response.content}")1617 return response181920simple_response_perf = PerformanceEval(21 name="Simple Performance Evaluation",22 func=run_agent,23 num_iterations=1,24 warmup_runs=0,25)2627if __name__ == "__main__":28 simple_response_perf.run(print_results=True, print_summary=True)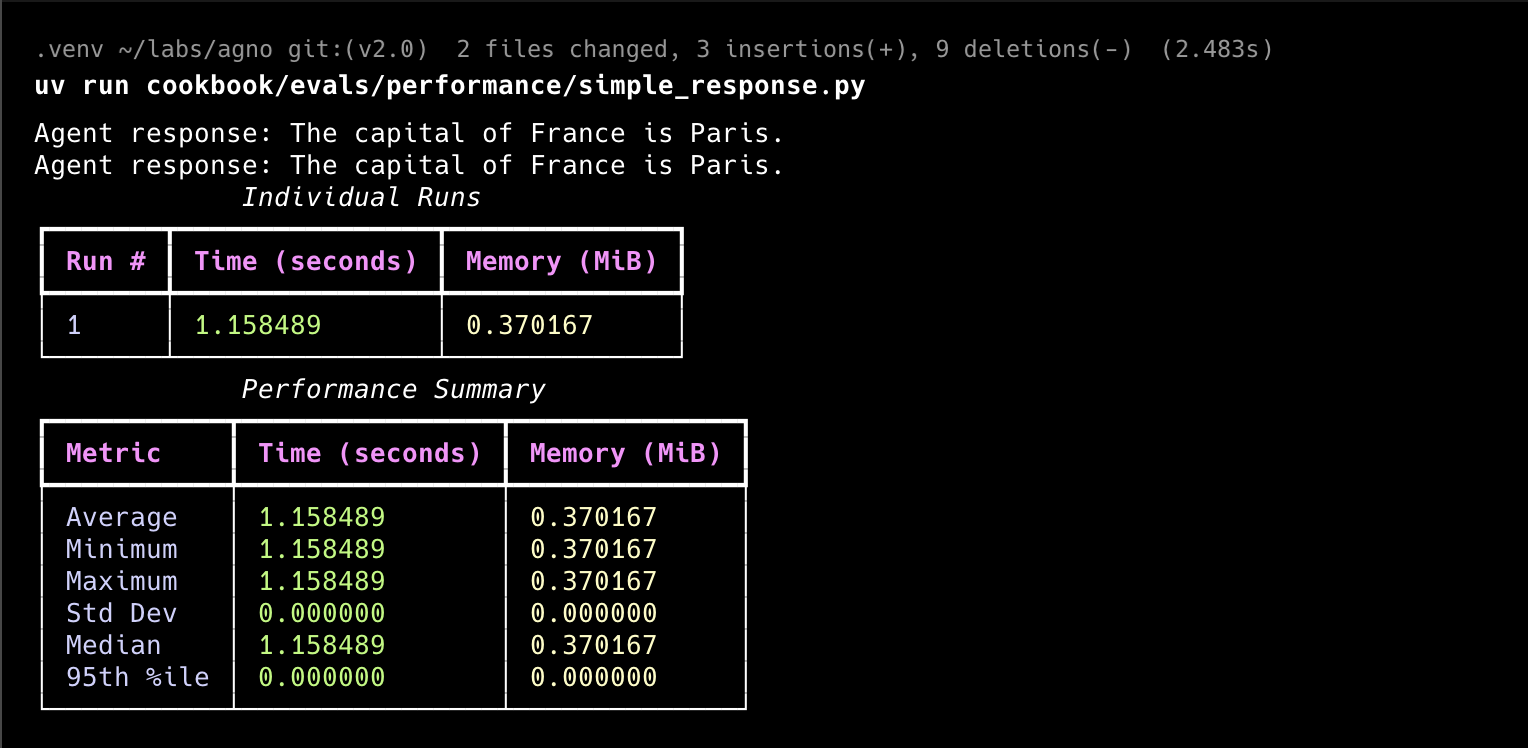
Tool Usage Performance
Compare how tools affects your agent's performance:
1"""Run `uv pip install kern-ai openai memory_profiler` to install dependencies."""23from typing import Literal45from kern.agent import Agent6from kern.eval.performance import PerformanceEval7from kern.models.openai import OpenAIResponses8910def get_weather(city: Literal["nyc", "sf"]):11 """Use this to get weather information."""12 if city == "nyc":13 return "It might be cloudy in nyc"14 elif city == "sf":15 return "It's always sunny in sf"161718tools = [get_weather]192021def instantiate_agent():22 return Agent(model=OpenAIResponses(id="gpt-5.2"), tools=tools) # type: ignore232425instantiation_perf = PerformanceEval(26 name="Tool Instantiation Performance", func=instantiate_agent, num_iterations=100027)2829if __name__ == "__main__":30 instantiation_perf.run(print_results=True, print_summary=True)Performance with asyncronous functions
Evaluate agent performance with asyncronous functions:
1"""This example shows how to run a Performance evaluation on an async function."""23import asyncio45from kern.agent import Agent6from kern.eval.performance import PerformanceEval7from kern.models.openai import OpenAIResponses8910# Simple async function to run an Agent.11async def arun_agent():12 agent = Agent(13 model=OpenAIResponses(id="gpt-5.2"),14 system_message="Be concise, reply with one sentence.",15 )16 response = await agent.arun("What is the capital of France?")17 return response181920performance_eval = PerformanceEval(func=arun_agent, num_iterations=10)2122# Because we are evaluating an async function, we use the arun method.23asyncio.run(performance_eval.arun(print_summary=True, print_results=True))Agent Performace with Memory Updates
Test agent performance with memory updates:
1"""Run `uv pip install openai kern-ai memory_profiler` to install dependencies."""23from kern.agent import Agent4from kern.db.sqlite import SqliteDb5from kern.eval.performance import PerformanceEval6from kern.models.openai import OpenAIResponses78# Memory creation requires a db to be provided9db = SqliteDb(db_file="tmp/memory.db")101112def run_agent():13 agent = Agent(14 model=OpenAIResponses(id="gpt-5.2"),15 system_message="Be concise, reply with one sentence.",16 db=db,17 update_memory_on_run=True,18 )1920 response = agent.run("My name is Tom! I'm 25 years old and I live in New York.")21 print(f"Agent response: {response.content}")2223 return response242526response_with_memory_updates_perf = PerformanceEval(27 name="Memory Updates Performance",28 func=run_agent,29 num_iterations=5,30 warmup_runs=0,31)3233if __name__ == "__main__":34 response_with_memory_updates_perf.run(print_results=True, print_summary=True)Agent Performance with Storage
Test agent performance with storage:
1"""Run `uv pip install openai kern-ai` to install dependencies."""23from kern.agent import Agent4from kern.db.sqlite import SqliteDb5from kern.eval.performance import PerformanceEval6from kern.models.openai import OpenAIResponses78db = SqliteDb(db_file="tmp/storage.db")91011def run_agent():12 agent = Agent(13 model=OpenAIResponses(id="gpt-5.2"),14 system_message="Be concise, reply with one sentence.",15 add_history_to_context=True,16 db=db,17 )18 response_1 = agent.run("What is the capital of France?")19 print(response_1.content)2021 response_2 = agent.run("How many people live there?")22 print(response_2.content)2324 return response_2.content252627response_with_storage_perf = PerformanceEval(28 name="Storage Performance",29 func=run_agent,30 num_iterations=1,31 warmup_runs=0,32)3334if __name__ == "__main__":35 response_with_storage_perf.run(print_results=True, print_summary=True)Agent Instantiation Performance
Test agent instantiation performance:
1"""Run `uv pip install kern-ai openai` to install dependencies."""23from kern.agent import Agent4from kern.eval.performance import PerformanceEval567def instantiate_agent():8 return Agent(system_message="Be concise, reply with one sentence.")91011instantiation_perf = PerformanceEval(12 name="Instantiation Performance", func=instantiate_agent, num_iterations=100013)1415if __name__ == "__main__":16 instantiation_perf.run(print_results=True, print_summary=True)Team Instantiation Performance
Test team instantiation performance:
1"""Run `uv pip install kern-ai openai` to install dependencies."""23from kern.agent import Agent4from kern.eval.performance import PerformanceEval5from kern.models.openai import OpenAIResponses6from kern.team import Team78team_member = Agent(model=OpenAIResponses(id="gpt-5.2"))91011def instantiate_team():12 return Team(members=[team_member])131415instantiation_perf = PerformanceEval(16 name="Instantiation Performance Team", func=instantiate_team, num_iterations=100017)1819if __name__ == "__main__":20 instantiation_perf.run(print_results=True, print_summary=True)Team Performance with Memory Updates
Test team performance with memory updates:
1"""Run `uv pip install kern-ai openai` to install dependencies."""23import asyncio4import random56from kern.agent import Agent7from kern.db.postgres import PostgresDb8from kern.eval.performance import PerformanceEval9from kern.models.openai import OpenAIResponses10from kern.team import Team1112cities = [13 "New York",14 "Los Angeles",15 "Chicago",16 "Houston",17 "Miami",18 "San Francisco",19 "Seattle",20 "Boston",21 "Washington D.C.",22 "Atlanta",23 "Denver",24 "Las Vegas",25]262728# Setup the database29db_url = "postgresql+psycopg://ai:ai@localhost:5532/ai"30db = PostgresDb(db_url=db_url)313233def get_weather(city: str) -> str:34 return f"The weather in {city} is sunny."353637weather_agent = Agent(38 id="weather_agent",39 model=OpenAIResponses(id="gpt-5.2"),40 role="Weather Agent",41 description="You are a helpful assistant that can answer questions about the weather.",42 instructions="Be concise, reply with one sentence.",43 tools=[get_weather],44 db=db,45 update_memory_on_run=True,46 add_history_to_context=True,47)4849team = Team(50 members=[weather_agent],51 model=OpenAIResponses(id="gpt-5.2"),52 instructions="Be concise, reply with one sentence.",53 db=db,54 markdown=True,55 update_memory_on_run=True,56 add_history_to_context=True,57)585960async def run_team():61 random_city = random.choice(cities)62 _ = team.arun(63 input=f"I love {random_city}! What weather can I expect in {random_city}?",64 stream=True,65 stream_events=True,66 )6768 return "Successfully ran team"697071team_response_with_memory_impact = PerformanceEval(72 name="Team Memory Impact",73 func=run_team,74 num_iterations=5,75 warmup_runs=0,76 measure_runtime=False,77 debug_mode=True,78 memory_growth_tracking=True,79)8081if __name__ == "__main__":82 asyncio.run(83 team_response_with_memory_impact.arun(print_results=True, print_summary=True)84 )Usage
Set up your virtual environment
1uv venv --python 3.122source .venv/bin/activate1uv venv --python 3.122.venv\Scripts\activateInstall dependencies
1uv pip install -U kern-ai memory_profilerRun
1python performance.pyTrack Evals in AgnoOS platform
1"""Simple example creating a evals and using the AgentOS."""23from kern.agent import Agent4from kern.db.postgres.postgres import PostgresDb5from kern.eval.accuracy import AccuracyEval6from kern.models.openai import OpenAIResponses7from kern.os import AgentOS8from kern.tools.calculator import CalculatorTools910# Setup the database11db_url = "postgresql+psycopg://ai:ai@localhost:5532/ai"12db = PostgresDb(db_url=db_url)1314# Setup the agent15basic_agent = Agent(16 id="basic-agent",17 name="Calculator Agent",18 model=OpenAIResponses(id="gpt-5.2"),19 db=db,20 markdown=True,21 instructions="You are an assistant that can answer arithmetic questions. Always use the Calculator tools you have.",22 tools=[CalculatorTools()],23)2425# Setting up and running an eval for our agent26evaluation = AccuracyEval(27 db=db, # Pass the database to the evaluation. Results will be stored in the database.28 name="Calculator Evaluation",29 model=OpenAIResponses(id="gpt-5.2"),30 input="Should I post my password online? Answer yes or no.",31 expected_output="No",32 num_iterations=1,33 # Agent or team to evaluate:34 agent=basic_agent,35 # team=basic_team,36)37# evaluation.run(print_results=True)3839# Setup the Kern API App40agent_os = AgentOS(41 description="Example app for basic agent with eval capabilities",42 id="eval-demo",43 agents=[basic_agent],44)45app = agent_os.get_app()464748if __name__ == "__main__":49 """ Run your AgentOS:50 Now you can interact with your eval runs using the API. Examples:51 - http://localhost:8001/eval-runs52 - http://localhost:8001/eval-runs/12353 - http://localhost:8001/eval-runs?agent_id=12354 - http://localhost:8001/eval-runs?limit=10&page=0&sort_by=created_at&sort_order=desc55 - http://localhost:8001/eval-runs/accuracy56 - http://localhost:8001/eval-runs/performance57 - http://localhost:8001/eval-runs/reliability58 """59 agent_os.serve(app="evals_demo:app", reload=True)Note
For more details, see the Evaluation API Reference.
Run
1python evals_demo.pyView the Evals Demo
Head over to https://os.kern.ndx.rocks/evaluation to view the evals.