Delegation
Control how the team leader delegates tasks to members.
When you call run() on a team, the leader decides how to handle the request: respond directly, use tools, or delegate to members.
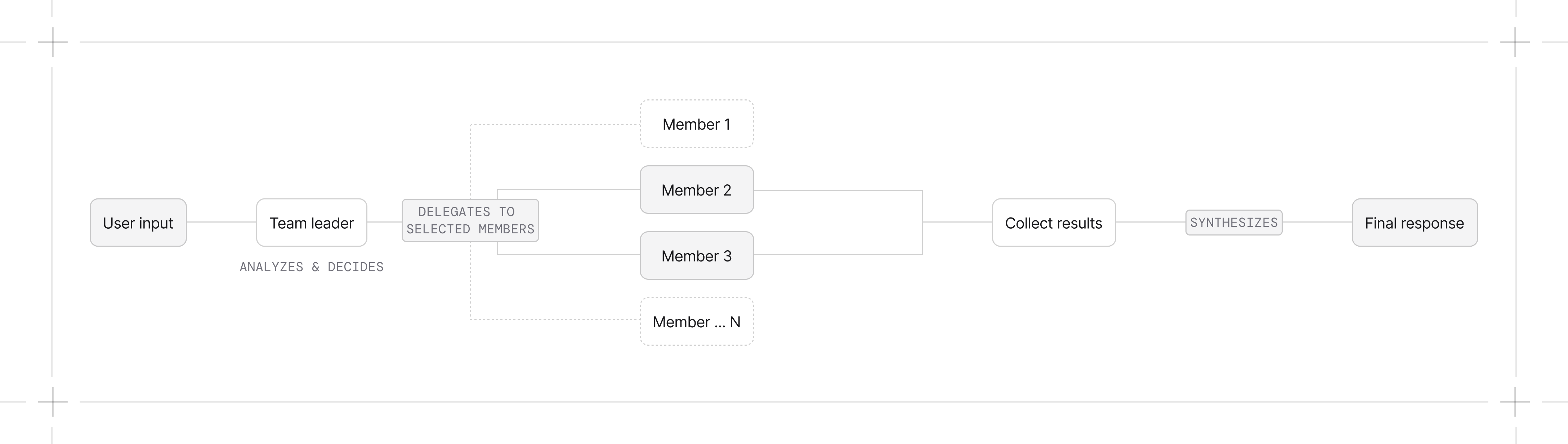
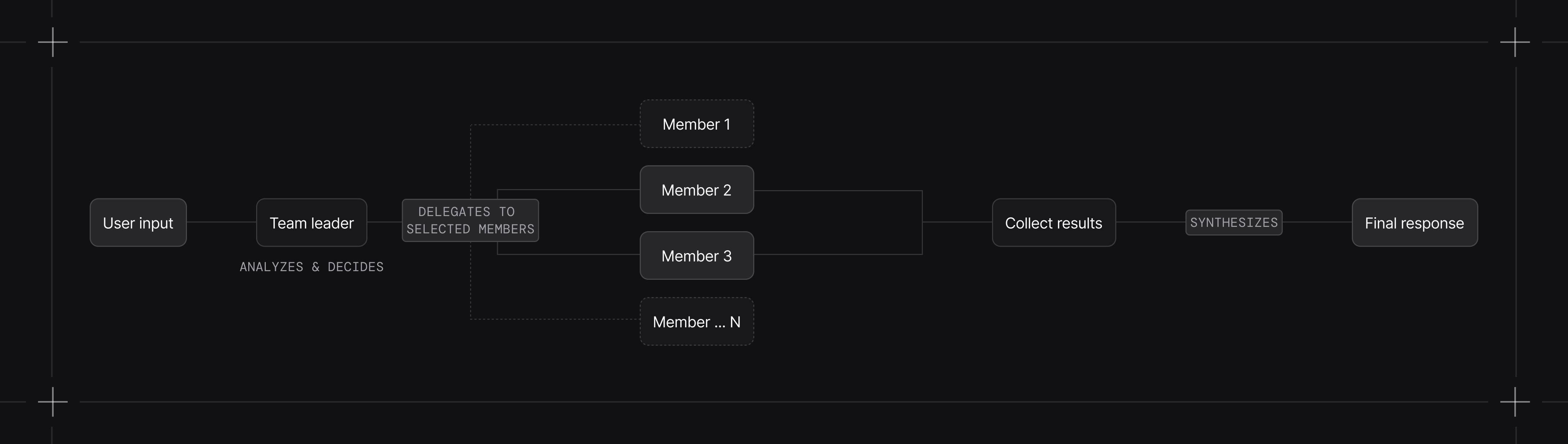
The default flow:
- Team receives user input
- Leader analyzes the input and decides which members to delegate to
- Leader formulates a task for each selected member
- Members execute and return results (concurrently in async mode)
- Leader synthesizes results into a final response
Modes define whether the leader delegates, routes to one member, broadcasts to all members, or runs a task loop. Modes are explicit orchestration patterns you can swap without changing member logic. Members can also be provided by callable factories and resolved at run time. See Callable Factories.
You can customize this flow with team modes:
| Mode | Configuration | Behavior |
|---|---|---|
| Coordinate (default) | mode=TeamMode.coordinate (or omit mode) | Leader selects members, formulates tasks, synthesizes results |
| Route | mode=TeamMode.route | Leader routes to one member and returns their response directly |
| Broadcast | mode=TeamMode.broadcast | Leader delegates the same task to all members simultaneously |
| Tasks | mode=TeamMode.tasks | Leader builds and executes a shared task list until the goal is complete |
Use TeamMode from kern.team.mode to set the mode explicitly. The legacy flags still work, but mode is the recommended approach.
Member selection and run tracking use member IDs. Set explicit id values on members for stable delegation identity.
Coordinate Mode (Default)
The leader controls everything: which members to use, what task to give them, and how to combine their outputs.
1from kern.team import Team2from kern.agent import Agent3from kern.team.mode import TeamMode4from kern.models.openai import OpenAIResponses5from kern.tools.hackernews import HackerNewsTools6from kern.tools.yfinance import YFinanceTools78team = Team(9 name="Research Team",10 model=OpenAIResponses(id="gpt-4o"),11 members=[12 Agent(name="News Agent", role="Get tech news", tools=[HackerNewsTools()]),13 Agent(name="Finance Agent", role="Get stock data", tools=[YFinanceTools()])14 ],15 mode=TeamMode.coordinate,16 instructions="Research the topic thoroughly, then synthesize findings into a clear report."17)1819team.print_response("What's happening with AI companies and their stock prices?")Use this when:
- Tasks need decomposition into subtasks
- You want quality control over the final output
- The leader should add context or reasoning to member outputs
Route Mode
The leader selects which member handles the request and returns the member's response directly. By default the leader can still craft the task; set determine_input_for_members=False to pass the user input through unchanged.
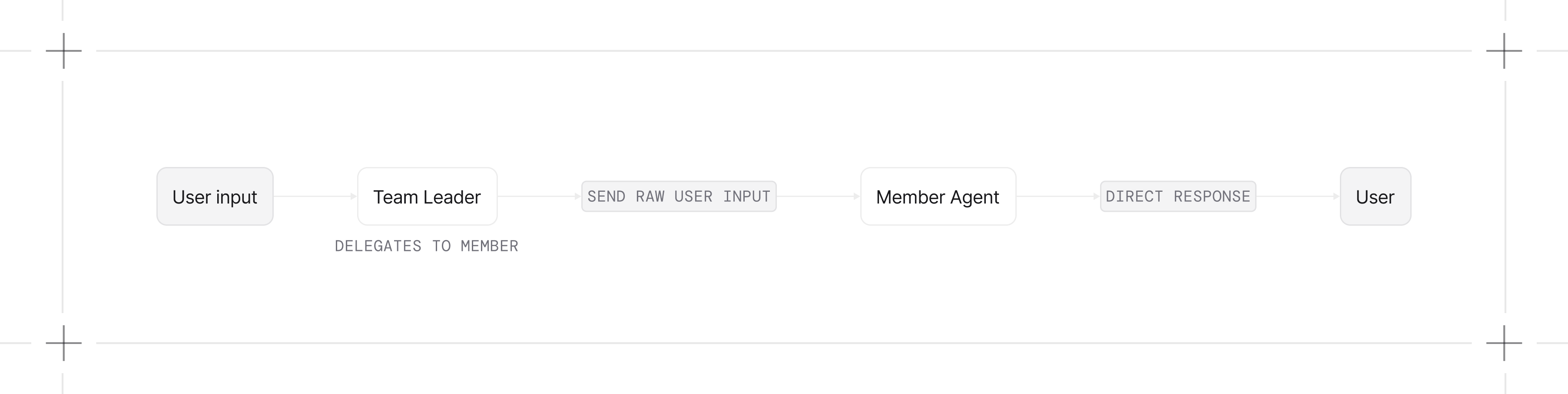
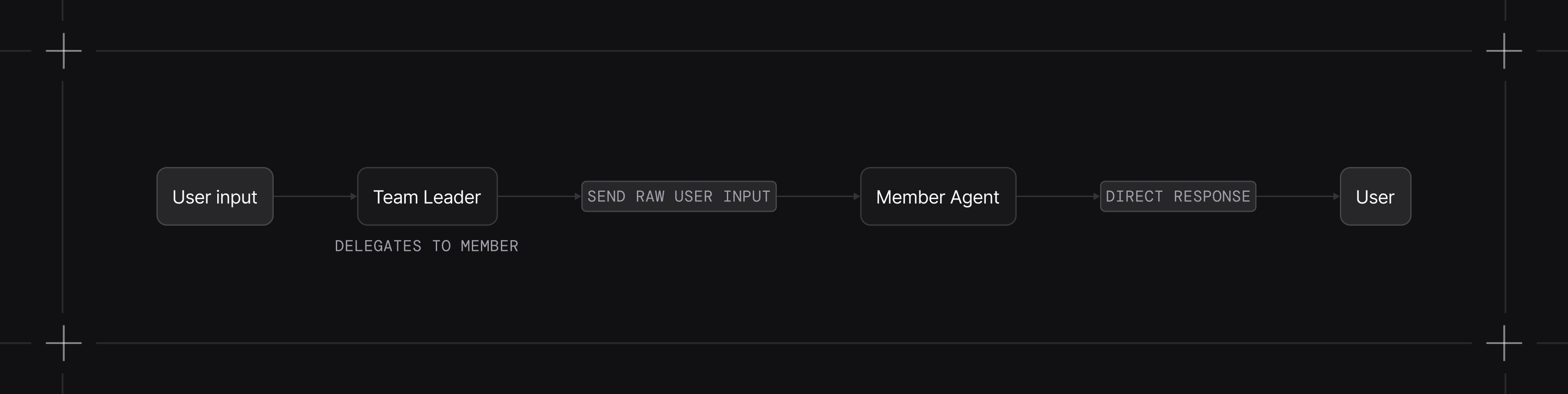
1from kern.team import Team2from kern.agent import Agent3from kern.team.mode import TeamMode4from kern.models.openai import OpenAIResponses56team = Team(7 name="Language Router",8 model=OpenAIResponses(id="gpt-4o"),9 members=[10 Agent(name="English Agent", role="Answer questions in English"),11 Agent(name="Japanese Agent", role="Answer questions in Japanese"),12 ],13 mode=TeamMode.route,14 determine_input_for_members=False # Pass user input unchanged to member15)1617team.print_response("How are you?") # Routes to English Agent18team.print_response("お元気ですか?") # Routes to Japanese AgentUse this when:
- You have specialized agents and want automatic routing
- The leader shouldn't modify the request or response
- You want lower latency (no synthesis step)
Legacy Configuration Flags
These flags still work, but are overridden by mode when set.
respond_directly=True: Return member responses without leader synthesis (maps to TeamMode.route).
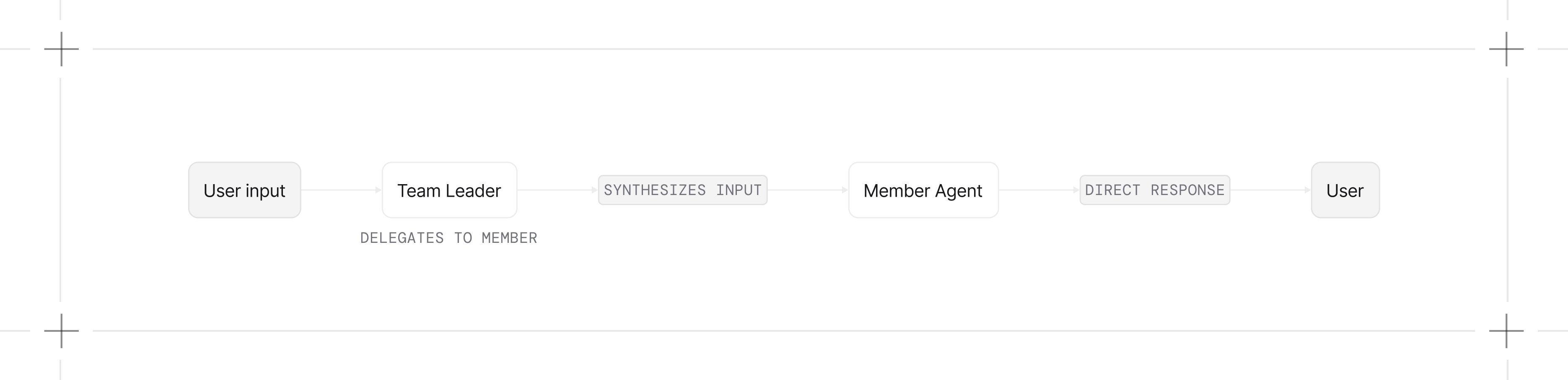
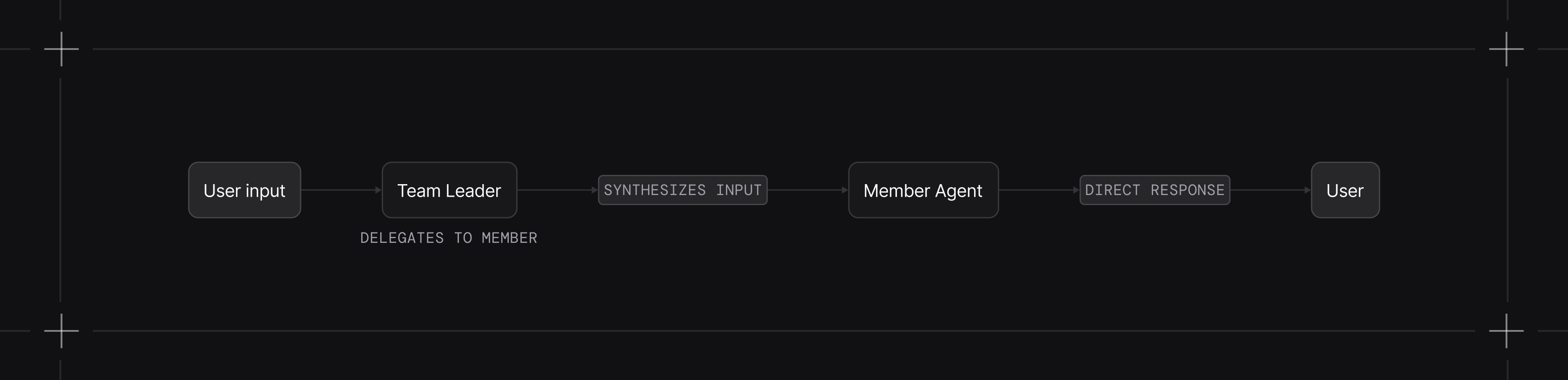
determine_input_for_members=False: Send user input directly to members instead of having the leader formulate a task (works with any mode).


Combine both for a full passthrough:
1team = Team(2 respond_directly=True,3 determine_input_for_members=False,4 ...5)Broadcast Mode
The leader delegates to all members at once. Useful for gathering multiple perspectives or parallel research.
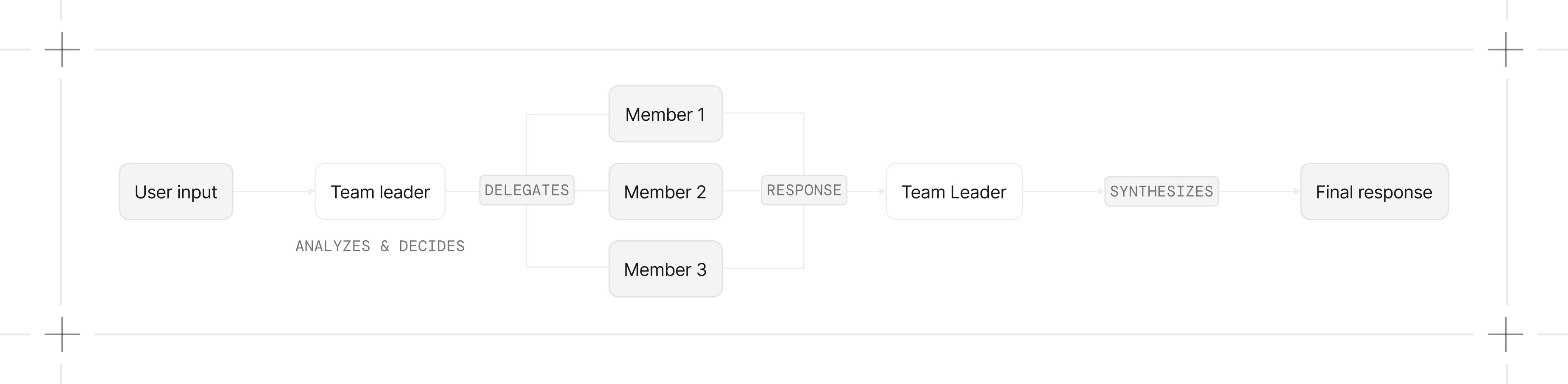
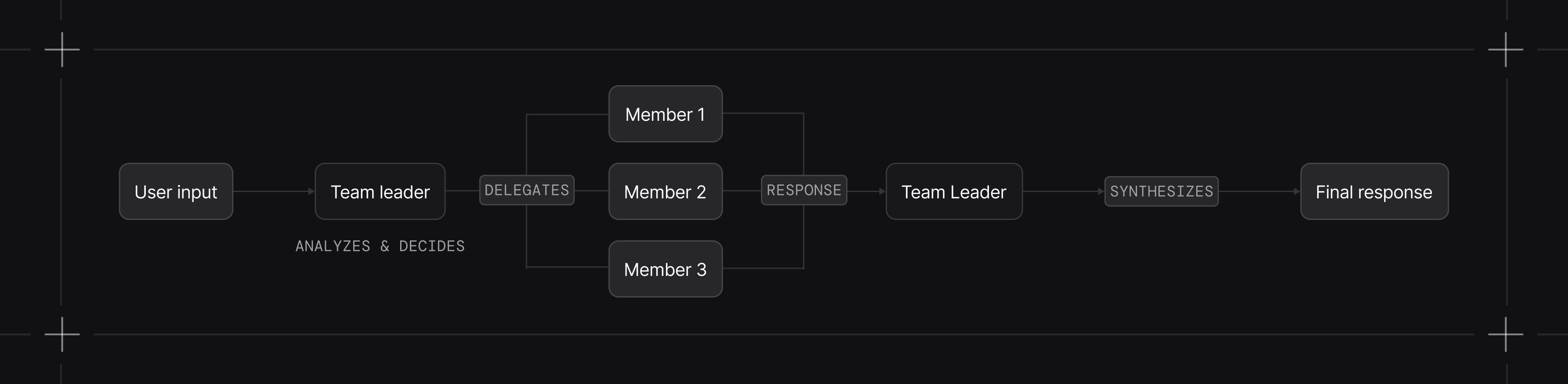
1import asyncio2from kern.team import Team3from kern.agent import Agent4from kern.team.mode import TeamMode5from kern.models.openai import OpenAIResponses6from kern.tools.hackernews import HackerNewsTools7from kern.tools.arxiv import ArxivTools8from kern.tools.duckduckgo import DuckDuckGoTools910team = Team(11 name="Research Team",12 model=OpenAIResponses(id="gpt-4o"),13 members=[14 Agent(name="HackerNews Researcher", role="Find discussions on HackerNews", tools=[HackerNewsTools()]),15 Agent(name="Academic Researcher", role="Find academic papers", tools=[ArxivTools()]),16 Agent(name="Web Researcher", role="Search the web", tools=[DuckDuckGoTools()]),17 ],18 mode=TeamMode.broadcast,19 instructions="Synthesize findings from all researchers into a comprehensive report."20)2122# Use async for concurrent execution23asyncio.run(team.aprint_response("Research the current state of AI agents"))Use this when:
- You want multiple perspectives on the same topic
- Members can work independently
- Parallel execution improves latency
If both delegate_to_all_members=True and respond_directly=True are set, broadcast wins and respond_directly is disabled.
Tasks Mode
Tasks mode is an autonomous loop where the leader decomposes the goal into tasks, executes them, and marks the goal complete.
1from kern.team import Team2from kern.agent import Agent3from kern.team.mode import TeamMode4from kern.models.openai import OpenAIResponses56team = Team(7 name="Ops Team",8 model=OpenAIResponses(id="gpt-4o"),9 members=[10 Agent(name="Research Agent", role="Collect findings"),11 Agent(name="Writer Agent", role="Draft the final report"),12 ],13 mode=TeamMode.tasks,14 max_iterations=615)1617team.print_response("Compile a short report on recent AI agent frameworks.")Structured Input
When using determine_input_for_members=False, you can pass structured Pydantic models directly to members:
1from pydantic import BaseModel, Field2from kern.team import Team3from kern.agent import Agent4from kern.models.openai import OpenAIResponses5from kern.tools.hackernews import HackerNewsTools67class ResearchRequest(BaseModel):8 topic: str9 num_sources: int = Field(default=5)1011research_agent = Agent(12 name="Research Agent",13 role="Research topics on HackerNews",14 tools=[HackerNewsTools()]15)1617team = Team(18 name="Research Team",19 model=OpenAIResponses(id="gpt-4o"),20 members=[research_agent],21 determine_input_for_members=False # Pass input directly to member22)2324request = ResearchRequest(topic="AI Agents", num_sources=10)25team.print_response(input=request)Production Considerations
Token Costs
Each mode has different token overhead:
| Mode | Coordination Cost | When to Use |
|---|---|---|
| Coordinate | High (decomposition + synthesis) | Quality matters more than cost |
| Route | Low (selection only) | Simple routing, cost-sensitive |
| Broadcast | Medium (synthesis only) | Parallel research, multiple perspectives |
| Tasks | High (planning + iterative loop) | Multi-step goals with dependencies |
Latency
- Coordinate: Sequential (leader thinks → members execute → leader synthesizes)
- Route: Fast (leader selects → member executes)
- Broadcast with async: Parallel member execution, but synthesis adds latency
- Tasks: Iterative; multiple cycles until tasks are complete or
max_iterationsis reached
Error Handling
What happens when a member fails?
- Coordinate: Leader can work with partial results from other members
- Route: Failure is returned directly to caller
- Broadcast: Leader synthesizes available results, may note missing data
- Tasks: Task list tracks failed/blocked tasks; the leader can retry or reassign until completion